How It Works¶
Lerim is trace-to-context infrastructure for repeated agent work.
Summary¶
The flow is:
- supported adapters read raw agent traces, or custom projects provide clean canonical traces
- supported traces are normalized; custom traces are already clean
- the trace ingestor extracts durable context records and drops low-value candidates
- the context curator cleans, merges, archives, and supersedes records
- the context graph agent links related records and assigns semantic clusters
- the context-brief compiler generates durable startup context from records
- working-memory generation renders recent record-version movement for short-term handoff
- run-clinic generation renders project-level diagnosis and improvement signals
- the context answerer retrieves records and answers questions
The current package includes supported source adapters and custom clean-trace folders. Customer deployments can adapt the input layer around business traces such as research briefs, support handoffs, incident investigations, revenue workflows, and custom internal agent logs.
For operational targets and scale boundaries, see Capacity and SLOs.
Overall Architecture¶
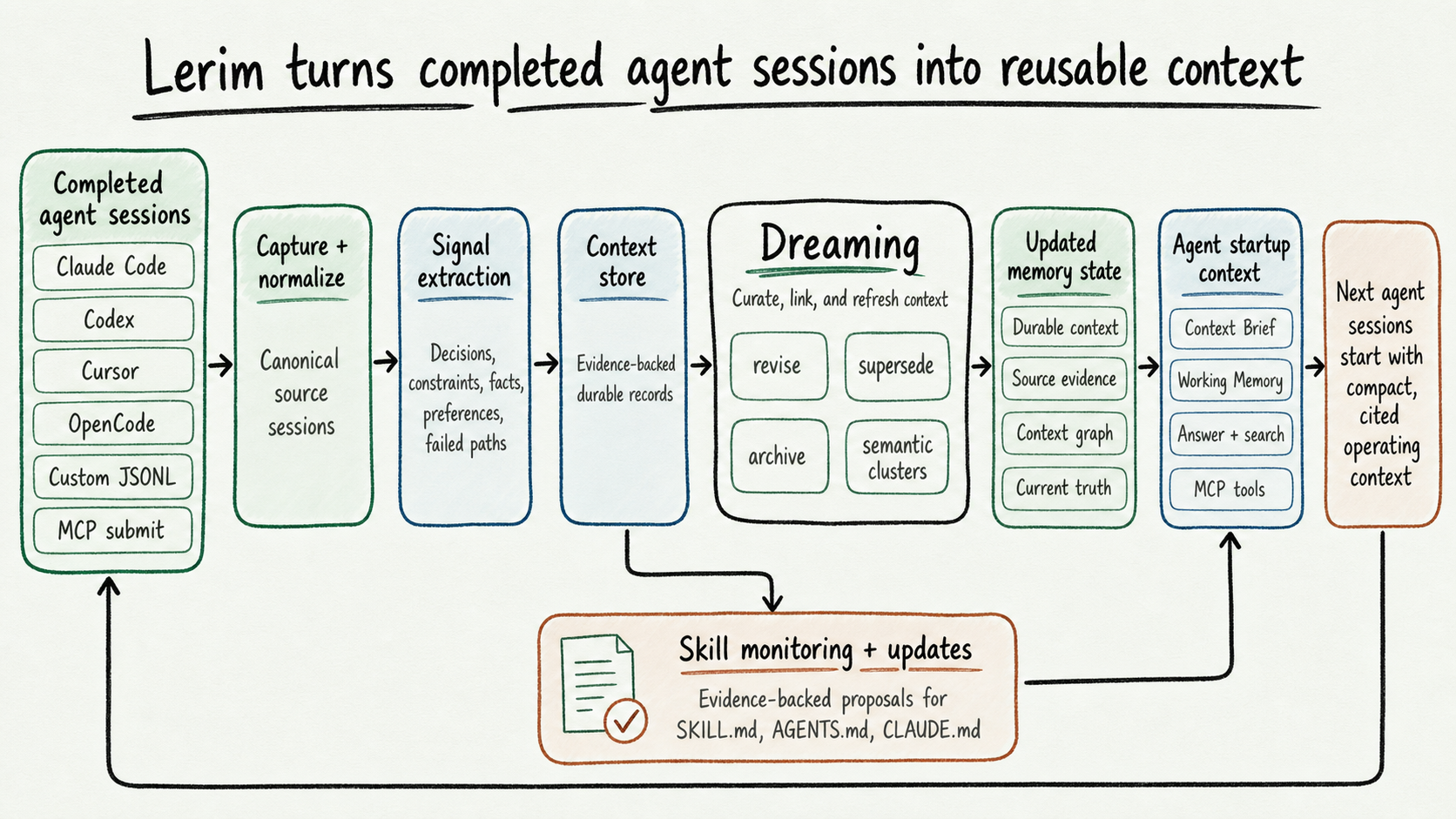
The sketchnote shows the product loop. The runtime architecture below maps the same loop onto Lerim's service components and derived artifacts.
flowchart TD
A["Agent activity sources"] --> B["Supported adapters or custom clean folders"]
B --> C["Session catalog and work queue"]
C --> D["Ingest"]
D --> E["Durable-signal filter"]
E --> F["Context writer"]
F --> G["Context Store"]
G --> H["Context curator"]
H --> G
G --> O["Context Graph"]
O --> P["Linked context projection"]
G --> I["Answer"]
I --> J["lerim answer / agent tools"]
G --> K["Context Brief"]
G --> L["Working Memory"]
K --> L["Startup context"]
L --> M["Future agent startup"]
N["Observability"] -. "operation and agent spans" .-> D
N -. "operation and agent spans" .-> H
N -. "operation and agent spans" .-> O
N -. "operation and agent spans" .-> I
N -. "operation and agent spans" .-> KImplementation notes¶
The sections below describe the current open-source runtime. Product and pilot conversations should usually start with the workflow boundary, source traces, review rules, and reusable context outputs.
Storage¶
Canonical storage is global:
~/.lerim/context.sqlite3— projects, sessions, records, versions, embeddings, and FTS~/.lerim/index/sessions.sqlite3— session catalog and queue~/.lerim/workspace/— run artifacts and logs~/.lerim/cache/traces/— compacted agent trace cache~/.lerim/models/embeddings/— local ONNX embedding model cache~/.lerim/models/huggingface/— Hugging Face library cache
Projects are currently scoped by project_id inside the database.
Agent runtime surface¶
Lerim does not expose raw SQL or file CRUD to agents.
The ingest flow reads deterministic trace windows, scans each window into typed findings, filters for durable signal, synthesizes records once, and persists them through the context store.
The expected product shape is:
Most routine traces should not create permanent context. A successful run can produce only an archived episode when there is no reusable signal.
Curation loads active records, builds semantic-neighbor clusters, reviews each cluster, reviews records not already targeted by a cluster action for single-record health issues, then applies validated archive, revise, and supersede operations through the context store.
Record lifecycle¶
Consolidation should preserve history while keeping active context clean:
- revise keeps the same record identity but writes a new version when the durable point is still valid and only needs clearer wording or fields
- supersede links an older record to the stronger replacement and closes the
old record's validity window with
valid_until - archive keeps the record as history but removes it from normal active retrieval
Old decisions should not disappear just because they are old. Age affects attention, not truth: active retrieval should favor current, confirmed, and query-relevant records, while still allowing historical lookup through explicit archive/version access. If a newer decision contradicts an older one, the older record should be superseded rather than silently rewritten into the new truth.
Context graph linking runs after curation. It loads active durable records, builds semantic candidate pairs, proposes sparse relationships, reviews those links, assigns persisted semantic clusters, and writes the graph projection for curation and planned cloud sync. The planned hosted dashboard can derive Louvain and combined visual lenses from those accepted links.
The context answerer follows a small retrieval plan:
- plan exact count/list/search retrieval actions
- execute read-only context queries
- write the final answer from retrieved records only
Retrieval blends semantic and lexical signals so agents get compact, relevant context rather than raw transcripts.
Search indexes are derived, not canonical:
recordsis the authoritative source for durable context.context_nodesandcontext_edgesare a derived graph projection over active records.records_ftsmirrors canonical record text for lexical retrieval.record_embeddingsmirrors canonical record search text for semantic retrieval.- Index health is measured with
record_count,fts_count,embedding_count, andmissing_embedding_count. - A fresh index has matching record, FTS, and embedding counts with no missing embeddings for the project scope being queried.
- If counts diverge,
answercan still run, but retrieval is operationally degraded until curation or write-time refresh rebuilds derived rows from canonical records.
Context Brief¶
Context Brief is also derived, not canonical. It renders a compact
CONTEXT_BRIEF.md from active project records so an agent can start with
long-term durable context and then query deeper only when needed.
flowchart LR
A["Context Store"] --> B["Context Brief synthesis"]
B --> C["dated run artifacts"]
C --> D["Current long-term startup context"]
D --> E["agent startup"]See Context Brief for the full generation flow.
Working Memory¶
Working Memory is another derived view. It renders WORKING_MEMORY.md from
recent record_versions, then resolves superseded records to the active
replacement record so agents see the current final decision alongside recent
change history.
See Working Memory for the short-term memory flow.
Why this design¶
The agent says what it wants to do. Python owns the storage mechanics.
That keeps:
- tool use smaller
- prompts cleaner
- invariants enforced in code
- training trajectories easier for smaller models later